
Projects
Identifying Risks and Opportunities in the Department of Defense Research Portfolio
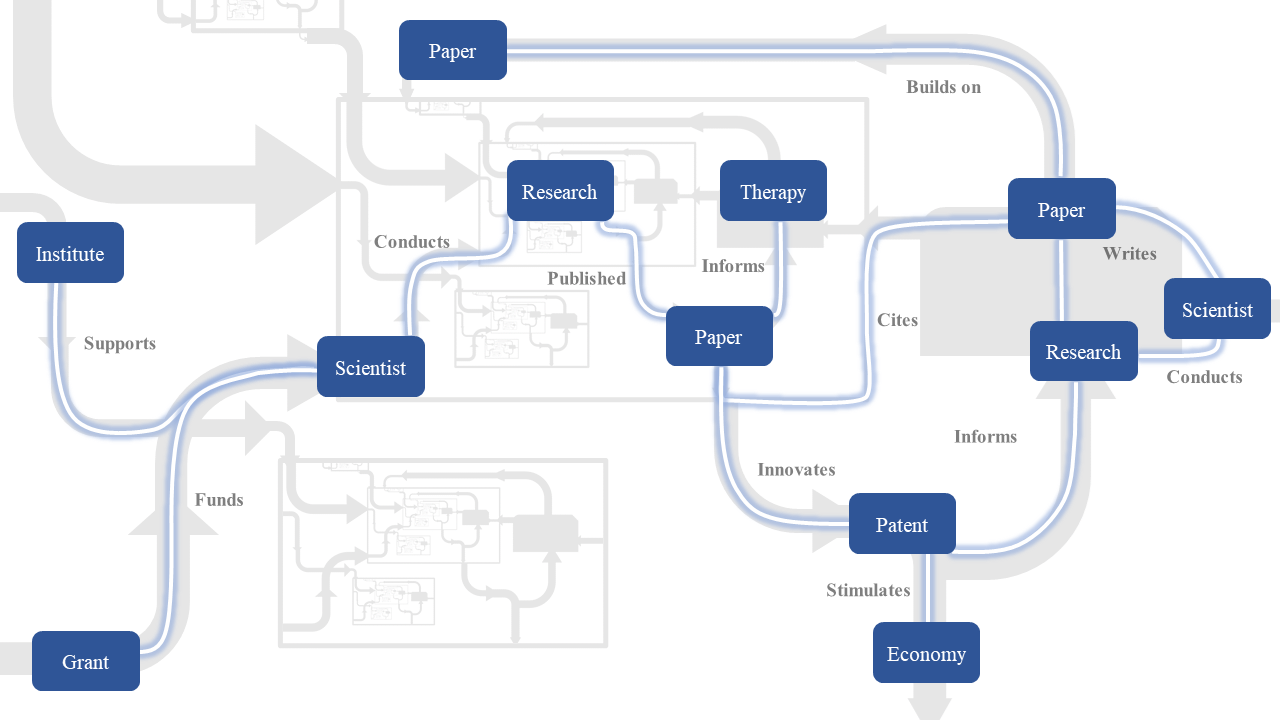
United States military superiority relies on harnessing the extensive technological advantages generated by our thriving innovation economy, stimulated by extensive federal investment. Effectively managing the Department of Defense (DoD) research portfolio is one way of ensuring that the United States maintains its technological advantage while achieving specific applied research goals.
To advance the frontier of evidence-based policymaking, some federal science funding agencies have developed scientific portfolio analysis: the quantitative analysis of linked data describing policy, grant text and metadata, the scientific workforce, their publications, and the flow of knowledge into basic or applied outcomes using citation analysis. This methodology introduces timely, relevant, and trusted evidence for consideration by agency leaders and enables funding agencies to characterize the scientific portfolio from both a global and local perspective.
Our team has helped build scientific portfolio analysis capacity at other agencies, and proposes to adapt and extend these approaches to the defense environment. This project will address current gaps in three Aims. First, we will construct an end-to-end database of linked DoD data from research funding to applied outcomes. Second, we will use these data to identify risks and opportunities in the research portfolio, such as potentially problematic overlap and measures of (mis)alignment with strategic priorities. Third, using machine learning and analysis of knowledge flow, we will quantify how resultant discoveries feed into downstream applied research goals, such as research into improvements in human health, or downstream invention and patenting activities.
Predicting Causal Citations Without Full Text
Citation analysis generally assumes that each citation documents causal knowledge transfer that informed the conception, design, or execution of the main experiments. Citations may exist for other reasons. In this project we identify a subset of citations that are unlikely to represent causal knowledge flow. Using a large, comprehensive feature set of open access data, we train a predictive model to identify such citations. The model relies only on the title, abstract, and reference set and not the full-text or future citation patterns, making it suitable for publications as soon as they are released, or those behind a paywall. We find that the model identifies, with high prediction scores, citations that were likely added during the peer review process, and conversely identifies with low prediction scores citations that are known to represent causal knowledge transfer.
Robustness of Evidence Reported in Preprints During Peer Review
Adoption of preprints dramatically expanded during the COVID-19 pandemic. Many have expressed concern that the risk of flawed decision-making is increased by relying on preprint data that would not survive peer review. We therefore asked how much the information presented in preprints is expected to change after review. We quantify attrition dynamics of over 1000 epidemiological estimates first reported in 100 matched preprints studying COVID-19. We find that 89% of point estimates persist through peer review. Of these, the correlation between preprint and published estimate values is extremely high at 0.99, and there is no systematic trend toward estimate inflation or deflation during review. Importantly, we find that expert peer review scores of preprint quality are not related to eventual publication in a peer reviewed journal. Uncertainty is reduced somewhat, as confidence interval ranges decrease by a small but statistically significant 7%. Therefore, the evidence base presented in preprints is highly stable, and where data change during review, uncertainty is expected to decrease by a small amount on average. This lends credence to the use of preprints, as one component of the biomedical research literature, in decision-making.